
La fréquence cumulative est la somme des fréquences absolues f, de la plus basse à celle qui correspond à une certaine valeur de la variable. À son tour, la fréquence absolue est le nombre de fois qu'une observation apparaît dans l'ensemble de données.
Évidemment, la variable d'étude doit être triable. Et comme la fréquence accumulée est obtenue en additionnant les fréquences absolues, il s'avère que la fréquence accumulée jusqu'aux dernières données doit coïncider avec le total d'entre elles. Sinon, il y a une erreur dans les calculs.

Habituellement, la fréquence cumulée est notée Fje (ou parfois nje), pour le distinguer de la fréquence absolue fje et il est important d'ajouter une colonne pour cela dans le tableau avec lequel les données sont organisées, appelé table de fréquences.
Cela facilite, entre autres, le suivi de la quantité de données comptées jusqu'à une certaine observation..
UN Fje il est également connu sous le nom de fréquence cumulée absolue. Si divisé par le total des données, nous avons le fréquence cumulative relative, dont la somme finale doit être égale à 1.
Index des articles
La fréquence cumulée d'une valeur donnée de la variable Xje est la somme des fréquences absolues f de toutes les valeurs inférieures ou égales à elle:
Fje = f1 + Fdeux + F3 +... Fje
En additionnant toutes les fréquences absolues, on obtient le nombre total de données N, soit:
F1 + Fdeux + F3 +…. + Fn = N
L'opération précédente est écrite de manière résumée au moyen du symbole de sommation:
∑ Fje = N
Les fréquences suivantes peuvent également être cumulées:
-Fréquence relative: s'obtient en divisant la fréquence absolue fje entre les données totales N:
Fr = fje / N
Si l'on ajoute les fréquences relatives de la plus basse à celle correspondant à une certaine observation, on a le fréquence relative cumulée. La dernière valeur doit être égale à 1.
-Fréquence relative cumulative en pourcentage: la fréquence relative accumulée est multipliée par 100%.
F% = (fje / N) x 100%
Ces fréquences sont utiles pour décrire le comportement des données, par exemple lors de la recherche des mesures de tendance centrale.
Pour obtenir la fréquence accumulée, il est nécessaire d'ordonner les données et de les organiser dans un tableau de fréquences. La procédure est illustrée dans la situation pratique suivante:
-Dans une boutique en ligne qui vend des téléphones portables, le record de ventes d'une certaine marque pour le mois de mars indiquait les valeurs suivantes par jour:
1; deux; 1; 3; 0; 1; 0; deux; 4; deux; 1; 0; 3; 3; 0; 1; deux; 4; 1; deux; 3; deux; 3; 1; deux; 4; deux; 1; 5; 5; 3
La variable est la nombre de téléphones vendus par jour et c'est quantitatif. Les données présentées de cette manière ne sont pas si faciles à interpréter, par exemple, les propriétaires du magasin pourraient être intéressés à savoir s'il y a une tendance, comme les jours de la semaine où les ventes de cette marque sont plus élevées..
Des informations comme celle-ci et plus encore peuvent être obtenues en présentant les données de manière ordonnée et en spécifiant les fréquences..
Pour calculer la fréquence cumulée, les données sont d'abord ordonnées:
0; 0; 0; 0; 1; 1; 1; 1; 1; 1; 1; 1; deux; deux; deux; deux; deux; deux; deux; deux; 3; 3; 3; 3; 3; 3; 4; 4; 4; 5; 5
Ensuite, une table est créée avec les informations suivantes:
-La première colonne de gauche avec le nombre de téléphones vendus, entre 0 et 5 et par ordre croissant.
-Deuxième colonne: fréquence absolue, c'est-à-dire le nombre de jours pendant lesquels 0 téléphone, 1 téléphone, 2 téléphones, etc. ont été vendus.
-Troisième colonne: la fréquence accumulée, constituée de la somme de la fréquence précédente plus la fréquence des données à considérer.
Cette colonne commence par les premières données de la colonne de fréquence absolue, dans ce cas, elle vaut 0. Pour la valeur suivante, ajoutez-la à la précédente. Il continue ainsi jusqu'à atteindre les dernières données de la fréquence accumulée, qui doivent coïncider avec les données totales.
Le tableau suivant présente la variable «nombre de téléphones vendus dans une journée», sa fréquence absolue et le calcul détaillé de sa fréquence cumulée.
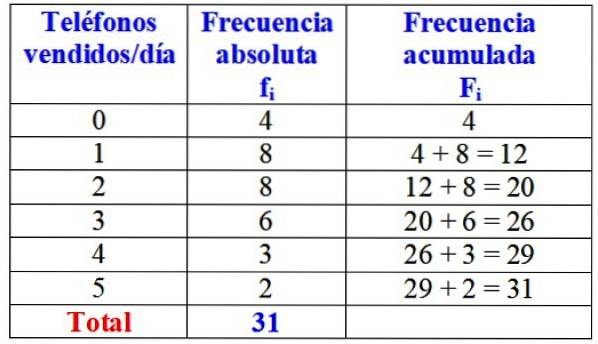
À première vue, on pourrait affirmer que de la marque en question, un ou deux téléphones sont presque toujours vendus par jour, puisque la fréquence absolue la plus élevée est de 8 jours, ce qui correspond à ces valeurs de la variable. Seulement pendant 4 jours du mois, ils n'ont pas vendu un seul téléphone.
Comme indiqué, le tableau est plus facile à examiner que les données individuelles collectées à l'origine.
Une distribution de fréquence cumulative est un tableau montrant les fréquences absolues, les fréquences cumulées, les fréquences relatives cumulées et les fréquences en pourcentage cumulées..
Bien qu'il y ait l'avantage d'organiser les données dans un tableau comme le précédent, si le nombre de données est très important, il peut ne pas être suffisant de les organiser comme indiqué ci-dessus, car s'il y a plusieurs fréquences, il devient quand même difficile de les organiser. interpréter.
Le problème peut être résolu en construisant un distribution de fréquence par intervalles, une procédure utile lorsque la variable prend un grand nombre de valeurs ou s'il s'agit d'une variable continue.
Ici, les valeurs sont regroupées en intervalles de même amplitude, appelés classe. Les classes se caractérisent par:
-Limite de classe: sont les valeurs extrêmes de chaque intervalle, il y en a deux, la limite supérieure et la limite inférieure. En général, la limite supérieure n'appartient pas à l'intervalle mais au suivant, tandis que la limite inférieure appartient.
-Marque de classe: est le milieu de chaque intervalle, et est pris comme valeur représentative de celui-ci.
-Largeur de la classe: Il est calculé en soustrayant la valeur des données les plus grandes et les plus petites (plage) et en divisant par le nombre de classes:
Largeur de classe = plage / nombre de classes
L'élaboration de la distribution de fréquence est détaillée ci-dessous..
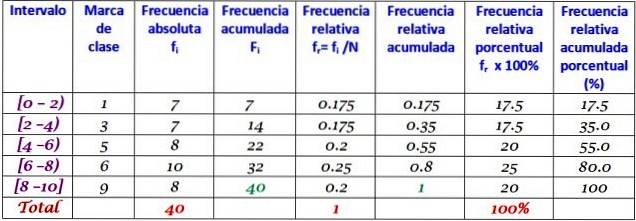
Cet ensemble de données correspond à 40 points d'un test de mathématiques, sur une échelle de 0 à 10:
0; 0; 0; 1; 1; 1; 1; deux; deux; deux; 3; 3; 3; 3; 4; 4; 4; 4; 5; 5; 5; 5; 6; 6; 6; 6; 7; 7; 7; 7; 7; 7; 8; 8; 8; 9; 9; 9, 10; dix.
Une distribution de fréquence peut être réalisée avec un certain nombre de classes, par exemple 5 classes. Il convient de garder à l'esprit que lors de l'utilisation de nombreuses classes, les données ne sont pas faciles à interpréter et le sens de la réalisation du regroupement est perdu.
Et si, au contraire, ils sont regroupés en très peu, alors l'information est diluée et une partie est perdue. Tout dépend de la quantité de données dont vous disposez.
Dans cet exemple, c'est une bonne idée d'avoir deux scores dans chaque intervalle, car il y a 10 scores et 5 classes seront créées. La plage correspond à la soustraction entre la note la plus élevée et la note la plus basse, la largeur de la classe étant:
Largeur de classe = (10-0) / 5 = 2
Les intervalles sont fermés à gauche et ouverts à droite (sauf le dernier), symbolisé respectivement par des crochets et des parenthèses. Ils ont tous la même largeur, mais ce n'est pas obligatoire, bien que ce soit le plus souvent.
Chaque intervalle contient une certaine quantité d'éléments ou une fréquence absolue, et dans la colonne suivante se trouve la fréquence accumulée, dans laquelle la somme est transportée. Le tableau montre également la fréquence relative fr (fréquence absolue entre le nombre total de données) et le pourcentage de fréquence relative fr × 100%.
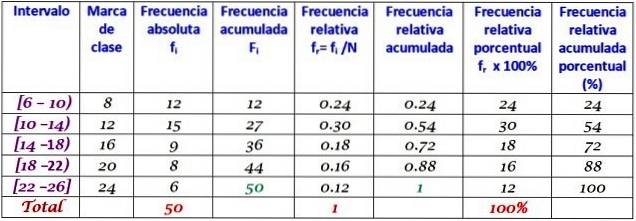
Une entreprise téléphonait quotidiennement à ses clients au cours des deux premiers mois de l'année. Les données sont les suivantes:
6, 12, 7, 15, 13, 18, 20, 25, 12, 10, 8, 13, 15, 6, 9, 18, 20, 24, 12, 7, 10, 11, 13, 9, 12, 15, 18, 20, 13, 17, 23, 25, 14, 18, 6, 14, 16, 9, 6, 10, 12, 20, 13, 17, 14, 26, 7, 12, 24, 7
Regroupez en 5 classes et construisez le tableau avec la distribution de fréquence.
La largeur de la classe est:
(26-6) / 5 = 4
Essayez de comprendre avant de voir la réponse.



Personne n'a encore commenté ce post.