Les degrés de liberté en statistique, il s'agit du nombre de composantes indépendantes d'un vecteur aléatoire. Si le vecteur a n composants et il y a p équations linéaires qui relient leurs composantes, puis les degré de liberté est n-p.
Le concept de degrés de liberté Il apparaît également en mécanique théorique, où ils sont à peu près équivalents à la dimension de l'espace où la particule se déplace, moins le nombre de liaisons..
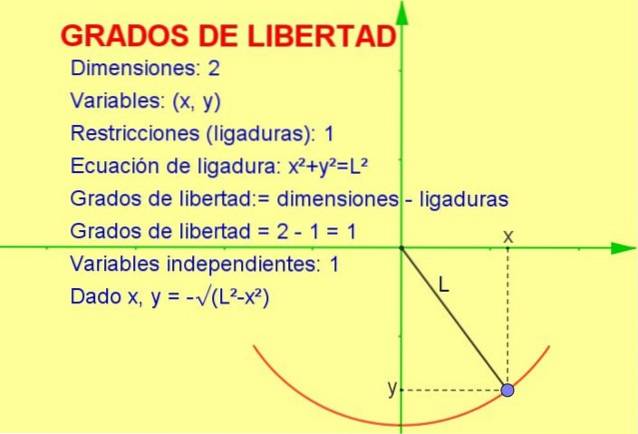
Cet article abordera le concept de degrés de liberté appliqué aux statistiques, mais un exemple mécanique est plus facile à visualiser sous forme géométrique.
Index des articles
Selon le contexte dans lequel il est appliqué, la façon de calculer le nombre de degrés de liberté peut varier, mais l'idée sous-jacente est toujours la même: dimensions totales moins nombre de restrictions.
Considérons une particule oscillante liée à une corde (un pendule) qui se déplace dans le plan vertical x-y (2 dimensions). Cependant, la particule est obligée de se déplacer sur la circonférence du rayon égal à la longueur de la corde.
Puisque la particule ne peut se déplacer que sur cette courbe, le nombre de degrés de liberté est 1. Cela peut être vu dans la figure 1.
La façon de calculer le nombre de degrés de liberté est de prendre la différence du nombre de dimensions moins le nombre de contraintes:
degrés de liberté: = 2 (dimensions) - 1 (ligature) = 1
Une autre explication qui nous permet d'arriver au résultat est la suivante:
-On sait que la position en deux dimensions est représentée par un point de coordonnées (x, y).
-Mais puisque le point doit satisfaire l'équation de la circonférence (xdeux + Ouideux = Ldeux) pour une valeur donnée de la variable x, la variable y est déterminée par ladite équation ou restriction.
Ainsi, une seule des variables est indépendante et le système a un (1) degré de liberté.
Pour illustrer ce que signifie le concept, supposons que le vecteur
X = (x1, Xdeux,..., Xn)
Que représente l'échantillon de n valeurs aléatoires normalement distribuées. Dans ce cas, le vecteur aléatoire X avoir n composants indépendants et donc on dit que X avoir n degrés de liberté.
Maintenant, construisons le vecteur r de déchets
r = (x1 -
Où
Donc la somme
(X1 -
C'est une équation qui représente une contrainte (ou une liaison) sur les éléments du vecteur r des résidus, car si n-1 composants du vecteur sont connus r, l'équation de contrainte détermine le composant inconnu.
Par conséquent, le vecteur r de dimension n avec la restriction:
∑ (xje -
Avoir (n - 1) degrés de liberté.
Encore une fois, il est appliqué que le calcul du nombre de degrés de liberté est:
degrés de liberté: = n (dimensions) - 1 (contraintes) = n-1
La variance sdeux est définie comme la moyenne du carré des écarts (ou résidus) de l'échantillon de n données:
sdeux = (r•r) / (n-1)
où r est le vecteur des résidus r = (x1 -
sdeux = ∑ (xje -
Dans tous les cas, il convient de noter que lors du calcul de la moyenne du carré des résidus, elle est divisée par (n-1) et non par n, car comme indiqué dans la section précédente, le nombre de degrés de liberté du vecteur r est (n-1).
Si pour le calcul de la variance ont été divisés par n au lieu de (n-1), le résultat aurait un biais très significatif pour les valeurs de n moins de 50.
Dans la littérature, la formule de variance apparaît également avec le diviseur n au lieu de (n-1), lorsqu'il s'agit de la variance d'une population.
Mais l'ensemble de la variable aléatoire des résidus, représentée par le vecteur r, Bien qu'il ait une dimension n, il n'a que (n-1) degrés de liberté. Cependant, si le nombre de données est suffisamment grand (n> 500), les deux formules convergent vers le même résultat.
Les calculatrices et les feuilles de calcul fournissent les deux versions de la variance et de l'écart type (qui est la racine carrée de la variance).
Notre recommandation, au vu de l'analyse présentée ici, est de toujours choisir la version avec (n-1) à chaque fois qu'il est nécessaire de calculer la variance ou l'écart type, pour éviter des résultats biaisés..
Certaines distributions de probabilité en variable aléatoire continue dépendent d'un paramètre appelé degré de liberté, est le cas de la distribution du Chi carré (χdeux).
Le nom de ce paramètre provient précisément des degrés de liberté du vecteur aléatoire sous-jacent auquel s'applique cette distribution.
Supposons que nous ayons g populations, à partir desquelles des échantillons de taille n sont prélevés:
X1 = (x11, x1deux,… X1n)
X2 = (x21, x2deux,… X2n)
... .
Xj = (xj1, xjdeux,… Xjn)
... .
Xg = (xg1, xgdeux,… Xgn)
Une population j qu'est-ce que la moyenne
La variable standardisée ou normalisée zjje est défini comme:
zjje = (xjje -
Et le vecteur Zj est défini comme ceci:
Zj = (zj1, zjdeux,..., zjje,..., zjn) et suit la distribution normale normalisée N (0,1).
Donc la variable:
Q = ((z11 ^ 2 + z21^ 2 +…. + zg1^ 2),…., (Z1n^ 2 + z2n^ 2 +…. + zgn^ 2))
suivre la distribution χdeux(g) appelé le distribution du chi carré avec degré de liberté g.
Lorsque vous souhaitez tester des hypothèses basées sur un certain ensemble de données aléatoires, vous devez connaître le nombre de degrés de liberté g pour pouvoir appliquer le test du Chi carré.
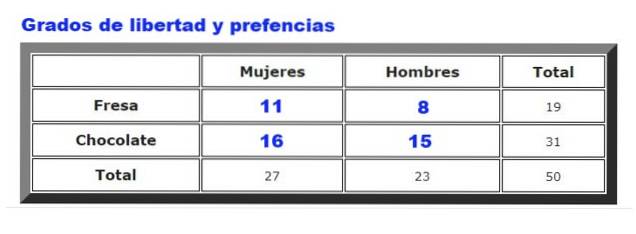
A titre d'exemple, les données collectées sur les préférences de glace au chocolat ou à la fraise chez les hommes et les femmes dans un certain glacier seront analysées. La fréquence à laquelle les hommes et les femmes choisissent la fraise ou le chocolat est résumée dans la figure 2.
Tout d'abord, le tableau des fréquences attendues est calculé, qui est préparé en multipliant le total de lignes pour lui total des colonnes, divisé par données totales. Le résultat est illustré dans la figure suivante:

Ensuite, nous procédons au calcul du Chi carré (à partir des données) en utilisant la formule suivante:
χdeux = ∑ (Fou alors - Fet)deux / Fet
Où Fou alors sont les fréquences observées (Figure 2) et Fet sont les fréquences attendues (Figure 3). La sommation couvre toutes les lignes et colonnes, ce qui dans notre exemple donne quatre termes.
Après avoir effectué les opérations, vous obtenez:
χdeux = 0,2043.
Maintenant, il est nécessaire de comparer avec le Chi carré théorique, qui dépend du nombre de degrés de liberté g.
Dans notre cas, ce nombre est déterminé comme suit:
g = (# lignes - 1) (# colonnes - 1) = (2 - 1) (2 - 1) = 1 * 1 = 1.
Il s'avère que le nombre de degrés de liberté g dans cet exemple est de 1.
Si vous souhaitez vérifier ou rejeter l'hypothèse nulle (H0: il n'y a pas de corrélation entre TASTE et GENDER) avec un niveau de signification de 1%, la valeur théorique du Chi carré est calculée avec le degré de liberté g = 1.
La valeur recherchée rend la fréquence accumulée (1 - 0,01) = 0,99, soit 99%. Cette valeur (qui peut être obtenue à partir des tableaux) est 6,636.
Lorsque le Chi théorique dépasse celui calculé, alors l'hypothèse nulle est vérifiée.
Autrement dit, avec les données collectées, Pas observé relation entre les variables TASTE et GENDER.


Personne n'a encore commenté ce post.