Ongle règle empirique C'est le résultat d'une expérience pratique et d'une observation réelle. Par exemple, il est possible de savoir quelles espèces d'oiseaux peuvent être observées à certains endroits à chaque période de l'année et à partir de cette observation une "règle" peut être établie qui décrit les cycles de vie de ces oiseaux.
En statistique, la règle empirique fait référence à la manière dont les observations sont regroupées autour d'une valeur centrale, la moyenne ou moyenne, en unités d'écart type..

Supposons que vous ayez un groupe de personnes avec une taille moyenne de 1,62 mètre et un écart type de 0,25 mètre, alors la règle empirique vous permettrait de définir, par exemple, combien de personnes seraient dans un intervalle de la moyenne plus ou moins un écart-type?
Selon la règle, 68% des données représentent plus ou moins un écart-type par rapport à la moyenne, c'est-à-dire que 68% des personnes du groupe auront une taille comprise entre 1,37 (1,62-0,25) et 1,87 (1,62 + 0,25) mètres.
Index des articles
La règle empirique est une généralisation du théorème de Tchebyshev et de la distribution normale.
Le théorème de Tchebyshev dit que: pour une valeur de k> 1, la probabilité qu'une variable aléatoire se situe entre la moyenne moins k fois l'écart type, et la moyenne plus k fois, l'écart type est supérieur ou égal à (1 - 1 / kdeux).
L'avantage de ce théorème est qu'il s'applique à des variables aléatoires discrètes ou continues avec n'importe quelle distribution de probabilité, mais la règle qui en est définie n'est pas toujours très précise, car elle dépend de la symétrie de la distribution. Plus la distribution de la variable aléatoire est asymétrique, moins son comportement sera ajusté à la règle.
La règle empirique définie à partir de ce théorème est:
Si k = √2, on dit que 50% des données sont dans l'intervalle: [µ - √2 s, µ + √2 s]
Si k = 2, on dit que 75% des données sont dans l'intervalle: [µ - 2 s, µ + 2 s]
Si k = 3, on dit que 89% des données sont dans l'intervalle: [µ - 3 s, µ + 3 s]
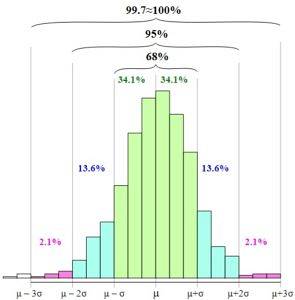
La distribution normale, ou cloche gaussienne, permet d'établir la règle empirique ou règle 68 - 95 - 99.7.
La règle est basée sur les probabilités d'occurrence d'une variable aléatoire dans des intervalles entre la moyenne moins un, deux ou trois écarts-types et la moyenne plus un, deux ou trois écarts-types..
La règle empirique définit les intervalles suivants:
68,27% des données se trouvent dans l'intervalle: [µ - s, µ + s]
95,45% des données se trouvent dans l'intervalle: [µ - 2s, µ + 2s]
99,73% des données se trouvent dans l'intervalle: [µ - 3s, µ + 3s]
Dans la figure, vous pouvez voir comment ces intervalles sont présentés et la relation entre eux lors de l'augmentation de la largeur de la base du graphique.
Par conséquent, l'application de la règle empirique à l'échelle d'une variable normale standard, z, définit les intervalles suivants:
68,27% des données sont dans l'intervalle: [-1, 1]
95,45% des données sont dans l'intervalle: [-2, 2]
99,73% des données sont dans l'intervalle: [-3, 3]
La règle empirique permet des calculs abrégés lorsque l'on travaille avec une distribution normale.
Supposons qu'un groupe de 100 étudiants a un âge moyen de 23 ans, avec un écart type de 2 ans. Quelles informations la règle empirique permet-elle?
L'application de la règle empirique implique de suivre les étapes:
Puisque la moyenne est de 23 et que l'écart-type est de 2, les intervalles sont:
[µ - s, µ + s] = [23 - 2, 23 + 2] = [21, 25]
[µ - 2s, µ + 2s] = [23 - 2 (2), 23 + 2 (2)] = [19, 27]
[µ - 3s, µ + 3s] = [23 - 3 (2), 23 + 3 (2)] = [17, 29]
(100) * 68,27% = 68 étudiants environ
(100) * 95,45% = 95 étudiants environ
(100) * 99,73% = environ 100 étudiants
Au moins 68 élèves ont entre 21 et 25 ans.
Au moins 95 élèves ont entre 19 et 27 ans.
Près de 100 étudiants ont entre 17 et 29 ans.
La règle empirique est un moyen rapide et pratique d'analyser les données statistiques, devenant de plus en plus fiable à mesure que la distribution se rapproche de la symétrie.
Son utilité dépend du domaine dans lequel il est utilisé et des questions posées. Il est très utile de savoir que l'apparition de valeurs de trois écarts types en dessous ou au-dessus de la moyenne est presque improbable, même pour des variables de distribution non normales, au moins 88,8% des cas sont dans l'intervalle de trois sigma.
En sciences sociales, un résultat généralement concluant est l'intervalle de la moyenne plus ou moins deux sigma (95%), alors qu'en physique des particules, un nouvel effet nécessite un intervalle de cinq sigma (99,99994%) pour être considéré comme une découverte..
Dans une réserve faunique, on estime qu'il y a en moyenne 16 000 lapins avec un écart type de 500 lapins. Si la distribution de la variable `` nombre de lapins dans la réserve '' est inconnue, est-il possible d'estimer la probabilité que la population de lapins soit comprise entre 15000 et 17000 lapins?
L'intervalle peut être présenté en ces termes:
15000 = 16000 - 1000 = 16000 - 2 (500) = µ - 2 s
17000 = 16000 + 1000 = 16000 + 2 (500) = µ + 2 s
Par conséquent: [15000, 17000] = [µ - 2 s, µ + 2 s]
En appliquant le théorème de Tchebyshev, il y a une probabilité d'au moins 0,75 que la population de lapins dans la réserve faunique se situe entre 15 000 et 17 000 lapins..
Le poids moyen des enfants d'un an dans un pays est normalement distribué avec une moyenne de 10 kilogrammes et un écart type d'environ 1 kilogramme.
a) Estimer le pourcentage d'enfants d'un an dans le pays qui ont un poids moyen entre 8 et 12 kilogrammes.
8 = 10 - 2 = 10 - 2 (1) = µ - 2 s
12 = 10 + 2 = 10 + 2 (1) = µ + 2 s
Par conséquent: [8, 12] = [µ - 2s, µ + 2s]
Selon la règle empirique, on peut affirmer que 68,27% des enfants d'un an dans le pays pèsent entre 8 et 12 kilogrammes.
b) Quelle est la probabilité de trouver un enfant d'un an pesant 7 kilogrammes ou moins?
7 = 10 - 3 = 10 - 3 (1) = µ - 3 s
On sait que 7 kilogrammes de poids représentent la valeur µ - 3s, et on sait que 99,73% des enfants pèsent entre 7 et 13 kilogrammes de poids. Cela ne laisse que 0,27% du total des enfants pour les extrêmes. La moitié d'entre eux, 0,135%, pèsent 7 kilogrammes ou moins et l'autre moitié, 0,135%, font 11 kilogrammes ou plus.
Ainsi, on peut conclure qu'il y a une probabilité de 0,00135 qu'un enfant pèse 7 kilogrammes ou moins.
c) Si la population du pays atteint 50 millions d'habitants et que les enfants d'un an représentent 1% de la population du pays, combien d'enfants d'un an pèseront entre 9 et 11 kilogrammes?
9 = 10 - 1 = µ - s
11 = 10 + 1 = µ + s
Par conséquent: [9, 11] = [µ - s, µ + s]
Selon la règle empirique, 68,27% des enfants d'un an dans le pays sont dans l'intervalle [µ - s, µ + s]
Il y a 500000 enfants d'un an dans le pays (1% de 50 millions), donc 341350 enfants (68,27% de 500000) pèsent entre 9 et 11 kilogrammes.



Personne n'a encore commenté ce post.