le mesures de la tendance centrale, de la dispersion et de la position, sont des valeurs utilisées pour interpréter correctement un ensemble de données statistiques. Ceux-ci peuvent être travaillés directement, comme ils sont obtenus à partir de l'étude statistique, ou ils peuvent être organisés en groupes de fréquence égale, ce qui facilite l'analyse..
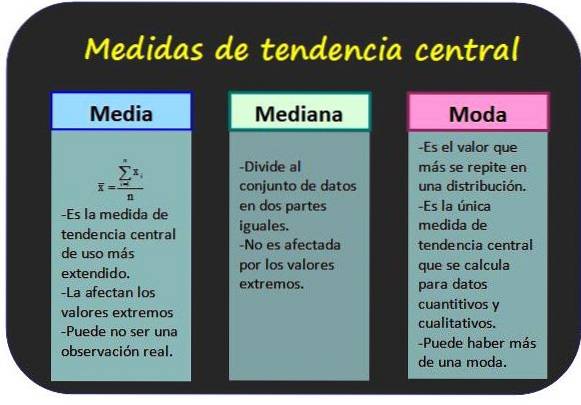
Ils permettent de savoir autour de quelles valeurs les données statistiques sont regroupées.
Elle est également connue sous le nom de moyenne des valeurs d'une variable et s'obtient en additionnant toutes les valeurs et en divisant le résultat par le nombre total de données.
Soit une variable x dont nous avons n données sans organisation ni regroupement, sa moyenne arithmétique se calcule comme suit:
Et en notation sommative:
Les propriétaires d'une auberge de tourisme de montagne ont l'intention de savoir combien de jours en moyenne les visiteurs séjournent dans les installations. Pour cela, un registre des jours de permanence de 20 groupes de touristes a été conservé, obtenant les données suivantes:
1; 1; deux; deux; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; deux; deux; 3; 4; 1
Le nombre moyen de jours de séjour des touristes est de:
Si les données de la variable sont organisées dans un tableau de fréquences absolues fje et les centres de classe sont x1, Xdeux,..., Xn, la moyenne est calculée par:
En notation sommative:
La médiane d'un groupe de n valeurs de la variable x est la valeur centrale du groupe, à condition que les valeurs soient ordonnées par ordre croissant. De cette manière, la moitié de toutes les valeurs sont inférieures au mode et l'autre moitié est supérieure..
Les cas suivants peuvent survenir:
-Nombre n de valeurs de la variable x impair: la médiane est la valeur qui se trouve juste au milieu du groupe de valeurs:
-Nombre n de valeurs de la variable x paire: dans ce cas, la médiane est calculée comme la moyenne des deux valeurs centrales du groupe de données:
Pour trouver la médiane des données de l'auberge de tourisme, elles sont d'abord classées du plus bas au plus élevé:
1; 1; 1; 1; 1; 1; 1; deux; deux; deux; deux; 3; 3; 3; 4; 4; 4; 4; 5; 5
Le nombre de données est pair, il y a donc deux données centrales: Xdix et XOnze et comme les deux valent 2, leur moyenne est aussi.
Médiane = 2
La formule suivante est utilisée:
Les symboles dans la formule signifient:
-c: largeur de l'intervalle contenant la médiane
-BM: borne inférieure du même intervalle
-Fm: nombre d'observations contenues dans l'intervalle auquel appartient la médiane.
-n: données totales.
-FBM: nombre d'observations avant que de l'intervalle contenant la médiane.
Le mode pour les données non groupées est la valeur avec la fréquence la plus élevée, tandis que pour les données groupées, c'est la classe avec la fréquence la plus élevée. La mode est considérée comme la donnée ou la classe la plus représentative de la distribution.
Deux caractéristiques importantes de cette mesure sont qu'un ensemble de données peut avoir plus d'un mode, et le mode peut être déterminé pour des données quantitatives et qualitatives..
En continuant avec les données du parador touristique, celui qui se répète le plus est 1, par conséquent, la chose la plus courante est que les touristes restent 1 jour dans le parador.
Les mesures de dispersion décrivent le degré de regroupement des données autour des mesures centrales.
Il est calculé en soustrayant les plus grandes données et les plus petites données. Si cette différence est grande, c'est le signe que les données sont dispersées, tandis que de petites valeurs indiquent que les données sont proches de la moyenne..
La fourchette des données du parador touristique est:
Plage = 5−1 = 4
Pour trouver la variance sdeux Il faut d'abord connaître la moyenne arithmétique, puis la différence au carré entre chaque donnée et la moyenne est calculée, toutes sont additionnées et divisées par le nombre total d'observations. Ces différences sont connues sous le nom de écarts.
La variance, toujours positive (ou nulle), indique à quel point les observations sont éloignées de la moyenne: si la variance est élevée, les valeurs sont plus dispersées que lorsque la variance est faible.
L'écart pour les données de l'auberge de tourisme est:
1; 1; deux; deux; 1; 4; 5; 1; 3; 4; 5; 4; 3; 1; 1; deux; deux; 3; 4; 1
Pour trouver la variance d'un ensemble de données groupées, les éléments suivants sont nécessaires: i) la moyenne, ii) la fréquence fje qui est le total des données dans chaque classe et iii) xje ou valeur de classe:
La desviación estándar es la raíz cuadrada positiva de la varianza, por lo que tiene una ventaja sobre la varianza: viene en las mismas unidades que la variable bajo estudio y así se tiene una idea más directa de lo cerca o lejos que está la variable de La moyenne.
Il est déterminé simplement en trouvant la racine carrée de la variance pour les données non groupées:
L'écart type des données de l'auberge de tourisme est:
s = √ (sdeux) = √1,95 = 1,40
Il est calculé en trouvant la racine carrée de la variance pour les données groupées:
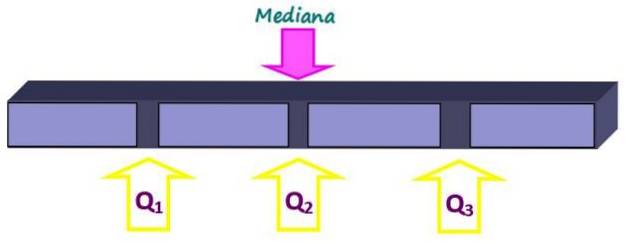
Les mesures de position divisent un ensemble ordonné de données en éléments de taille égale. La médiane, en plus d'être une mesure de la tendance centrale, est aussi une mesure de la position, puisqu'elle divise le tout en deux parties égales. Mais des pièces plus petites peuvent être obtenues avec des quartiles, des déciles et des centiles.
Les quartiles divisent l'ensemble en quatre parties égales, chacune contenant 25% des données. Ils sont notés Q1, Qdeux et alors3 et la médiane est le quartile Qdeux. De cette façon, 25% des données sont inférieures au quartile Q.1, 50% sous le quartile Qdeux ou médiane et 75% sous le quartile Q3.
Les données sont classées et le total est divisé en 4 groupes avec le même nombre de données chacun. La position du premier quartile est trouvée par:
Q1 = (n + 1) / 4
Où n est le total des données. Si le résultat est un entier, les données correspondant à cette position sont localisées, mais si elle est décimale, les données correspondant à la partie entière sont moyennées avec la suivante, ou pour plus de précision, elles sont interpolées linéairement entre lesdites données.
La position du premier quartile Q1 pour les données du parador touristique est:
Q1 = (n + 1) / 4 = (20 + 1) / 4 = 5,25
Il s'agit de la position du quartile 1 et comme le résultat est décimal, les données X sont recherchées5 et X6, qui sont respectivement X5 = 1 et X6 = 1 et sont moyennés, ce qui donne:
Premier quartile = 1
1; 1; 1; 1; 1; 1; 1; deux; deux; deux; deux; 3; 3; 3; 4; 4; 4; 4; 5; 5.
La position du deuxième quartile Qdeux c'est:
Qdeux = 2 (n + 1) / 4 = 10,5
Quelle est la moyenne entre Xdix et XOnze et correspond à la médiane:
Deuxième quartile = Médiane = 2
La position du troisième quartile est calculée par:
Q3 = 3 (n + 1) / 4 = 3 (20 + 1) / 4 = 15,75
Il est également décimal, donc X est en moyennequinze et X16:
1; 1; 1; 1; 1; 1; 1; deux; deux; deux; deux; 3; 3; 3; 4; 4; 4; 4; 5; 5.
Mais puisque les deux valent 4:
Troisième quartile = 4
La formule générale pour la position des quartiles dans les données non groupées est:
Qk = k (n + 1) / 4
Avec k = 1,2,3.
Ils sont calculés de manière similaire à la médiane:

L'explication des symboles est:
-BQ: limite inférieure de l'intervalle contenant le quartile
-c: largeur de cet intervalle
-Fquelle: nombre d'observations contenues dans l'intervalle quartile.
-n: données totales.
-FBQ: nombre de données avant que de l'intervalle contenant le quartile.
Les déciles et les centiles divisent l'ensemble de données en 10 parties égales et 100 parties égales respectivement, et leur calcul est effectué de la même manière que celui des quartiles..
Les formules sont utilisées respectivement:
rék = k (n + 1) / 10
Avec k = 1,2,3… 9.
Décile D5 doit être égal à la médiane.
Pk = k (n + 1) / 100
Avec k = 1,2,3… 99.
Le percentile Pcinquante doit être égal à la médiane.
Dans l'exemple de l'auberge touristique, la position du D3 c'est:
ré3 = 3 (20 + 1) / 10 = 6,3
Puisqu'il s'agit d'un nombre décimal, X est en moyenne6 et X7, tous deux égaux à 1:
1; 1; 1; 1; 1; 1; 1; deux; deux; deux; deux; 3; 3; 3; 4; 4; 4; 4; 5; 5
Cela signifie que 3 dixièmes des données sont inférieures à X7 = 1 et les autres ci-dessus.
Les formules sont analogues à celles des quartiles. D est utilisé pour désigner les déciles et P pour les percentiles, et les symboles sont interprétés de la même manière:
Lorsque les données sont distribuées symétriquement et que la distribution est unimodale, il existe une règle appelée règle empirique ou alors règle 68 - 95 - 99, qui les regroupe dans les intervalles suivants:
Dans quel intervalle se trouvent 95% des données du parador touristique?
Ils sont dans l'intervalle: [2,5−1,40; 2,5 + 1,40] = [1,1; 3.9].



Personne n'a encore commenté ce post.